
Бизнес-потребности: перенос нагрузки работы аналитиков с ресурсоёмких рутинных операций на работу в наиболее интеллектуально нагруженные области патентной аналитики.
Профиль трека: разработка собственных кокпитов, интерактивных панелей управления, деревьев решений и алгоритмов сценарного анализа для автоматизации ресурсоёмких рутинных операций патентной аналитики, связанных с тегированием, стандартизацией, сбором и гармонизацией больших объёмов данных (патентных и непатентных).
Специфика трека: разработка новых алгоритмов, программ и интерфейсов для областей, которые забыты или трудно реализуемы в существующих профессиональных системах патентной аналитики.
Главные эффекты трека: С одной стороны, это переключение аналитиков с рутинных задач на творческие, с другой стороны, вывод в пространство патентной аналитики качественно новых ценных показателей, например, захват патентами новых рынков.
Кроме того, аналитики начинают решать классические задачи патентной аналитики с применением более интеллектуальных алгоритмов и методов. Такими задачами выступают исследование взаимосвязи технологий между собой через патентное цитирование, исследование динамики и прогноз развития, ключевые изменения за последние несколько лет, направления развития компаний-лидеров и другие задачи.
Описание
Трек «Интеллектуальный анализ данных» – реакция Проектного офиса ФИПС на существенное увеличение числа параллельных проектов и стратегические планы по реализации уникальных алгоритмов анализа, отсутствующих даже у признанных поставщиков систем патентной аналитики.
Это направление появилось и развивается в Проектном офисе ФИПС с 2022 года. Разрабатываемые функции тестируются и применяются в текущих консалтинговых проектах, реализуемых в разнообразных отраслях и областях применения.
Разработка дополнительных функций нужна в проектах, которые относятся к областям с чрезмерно большим для ручной обработки числом запатентованных технологий, и проектах, которые предполагают масштабный многоаспектный анализ.
Такие проекты требуют, с одной стороны, обработки больших массивов данных и использования широкого спектра стандартных для патентного анализа показателей, с другой стороны, введения новых показателей и систем для исследования специфики разных областей, составление прогнозов и рекомендаций с качественной доказательной базой.

Использование продвинутых инструментов, таких как деревья решений и обработка естественных языков, давно практикуется в разных областях анализа данных от медицины до добычи нефти. Они позволяют, в частности, давать прогнозы изменения состояния исследуемых объектов (вероятности наступления определенных возможны событий) и принимать решения, принимая сложные и неочевидные взаимосвязи между событиями и объектами.
Применительно к патентам их использование затруднено множеством факторов, в числе которых можно отметить следующие.
- Наиболее ценная информация в патентах – неструктурированная. Это описание технологии в текстовых полях документов (реферат, формула, описание). На настоящий момент технологии искусственного интеллекта, используемые для их анализа, не обеспечивают достаточного уровня точности и полноты (F-measure, precision & recall). Дополнительными научно-техническими проблемами являются глобальная идентификация объектов (global disambiguation) и наименование объектов (naming).
- Данных часто недостаточно для построения полноценных предсказательных моделей, особенно в новых областях с небольшим числом запатентованных разработок. Именно такие области часто интересны компаниям на предмет выявления возможных ниш для развития с опережением ближайших конкурентов.
- При анализе патентных документов важно учитывать юридическую сторону, в частности, различные особенности патентования в отдельных странах. В процессе экспертного анализа качество системы интеллектуальной собственности и национальные стратегии патентования принимаются во внимание. В процессе анализа машинным способом эта проблема должна также решаться отдельно.
- Постановка задачи для анализа патентных документов часто описывается в терминах решения конкретных производственных задач (например, задача диверсификации производства / замены недоступных компонентов доступными альтернативами и др.), что требует предварительной формализации и систематизации экспертным образом.
Вместе с тем, по мере роста популярности патентной аналитики в качестве инструмента поддержки принятия решений, растет запрос на внедрение современных методов анализа данных, которые позволили бы обрабатывать большие патентные коллекции и сократить время, требуемое для проведения полноценного анализа.
Принимая во внимание эту растущую потребность, а также перечисленные выше особенности, Проектный офис ФИПС занимается разработкой собственных программных продуктов.
Разработка алгоритмов ведется на основе языка программирования Python, в рамках которого реализовано большинство необходимых для углубленного анализа данных функций. Для хранения больших массивов данных, таких как список индексов Международной патентной классификации или актуальный перечень стандартизованных с учетом организационных изменений названий компаний и их дочерних структур, используется облачный сервер. Часть функций реализуется через программные интерфейсы приложений (API).
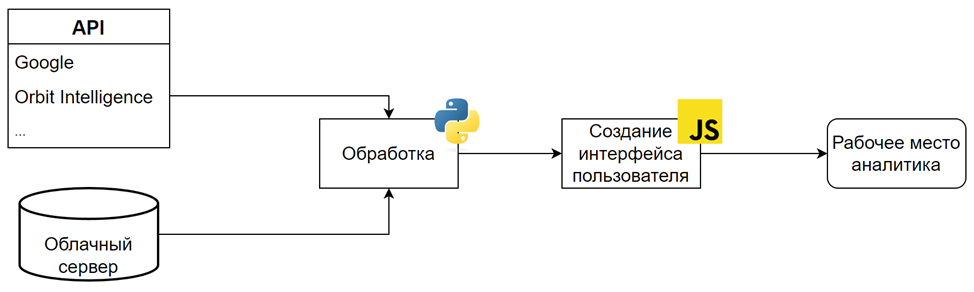
Результатом работы выступает интегрированное рабочее место аналитика – приложение, в котором реализован набор гибких функций для автоматизации рутинных операций и осуществления дополнительного анализа.
На данный момент в формате алгоритма реализованы такие функции, как
- функции поддержки поиска (перевод терминов и расширительный поиск синонимов для дополнения поисковых запросов);
- функции обработки матрицы тегирования для раздела «Технический анализ» (приведение к стандартному виду, сборка матрицы тегирования для сверхбольших коллекций в несколько десятков тысяч патентных семейств), находятся в стадии разработки интерфейса;
- дополнительная аналитика (автоматически собираемый отчет по ценному патенту, иерархическая группировка патентных семейств по МПК).

Параллельно ведется работа по следующим направлениям:
- получение доступа к патентным базам данных через программный интерфейс приложения;
- формализация показателей зрелости технологий для дальнейшего использования в алгоритмах классификации технологий по степени зрелости;
- расширение существующих аналитических представлений;
- разработка комплексного показателя ценности патентов, который мог бы применяться в различных областях;
- углубленный анализ патентного цитирования;
- …
К разработке привлекаются специалисты в области искусственного интеллекта и анализа данных, профессиональные ИТ-архитекторы с опытом работы над сложными аналитическими системами, дизайнеры и эксперты с опытом разработки сложных аналитических продуктов на основе патентной информации.
Главная ценность трека «Интеллектуальный анализ данных» заключается в ориентации на конкретные практические задачи.
Разрабатываемые алгоритмы тестируются в реальных условиях на реальных патентных коллекциях. Процесс разработки полноценного программного обеспечения, включающий тестирование и проработку ошибок, может занимать не один год. Благодаря используемому подходу промежуточные результаты этого процесса обогащают текущие проекты и отрабатываются «на ходу» без необходимости ожидания окончания работ.
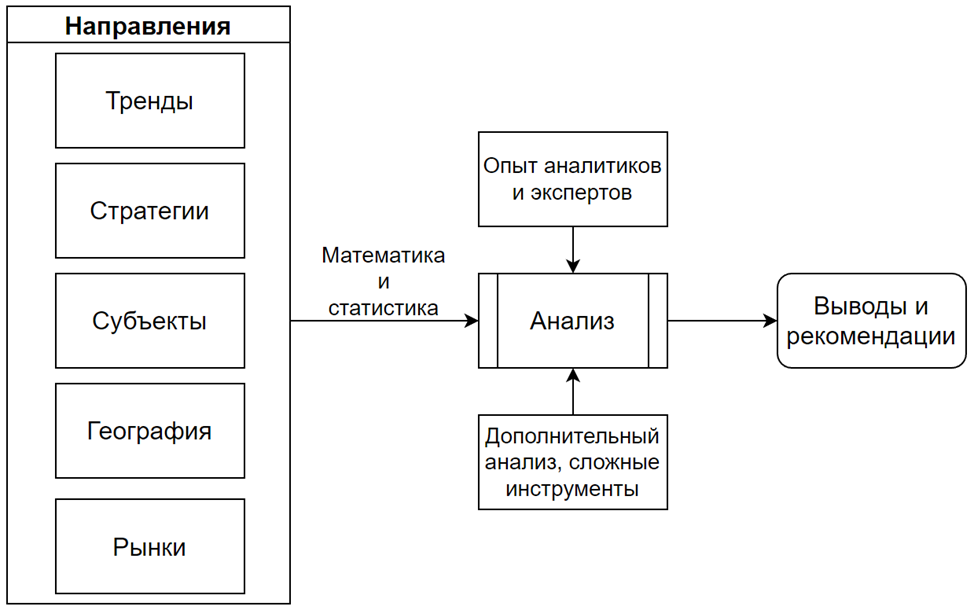
Аналитики, в свою очередь, быстро получают готовые инструменты, которые позволяют снять дополнительную нагрузку и переключиться на наиболее интеллектуальные аспекты работы.
Проектный офис ФИПС будет продолжать разработку собственных алгоритмов интеллектуального анализа данных с опорой на лучший мировой опыт и учетом специфики патентной информации. Следите за обновлениями в блоге и в телеграм-канале.